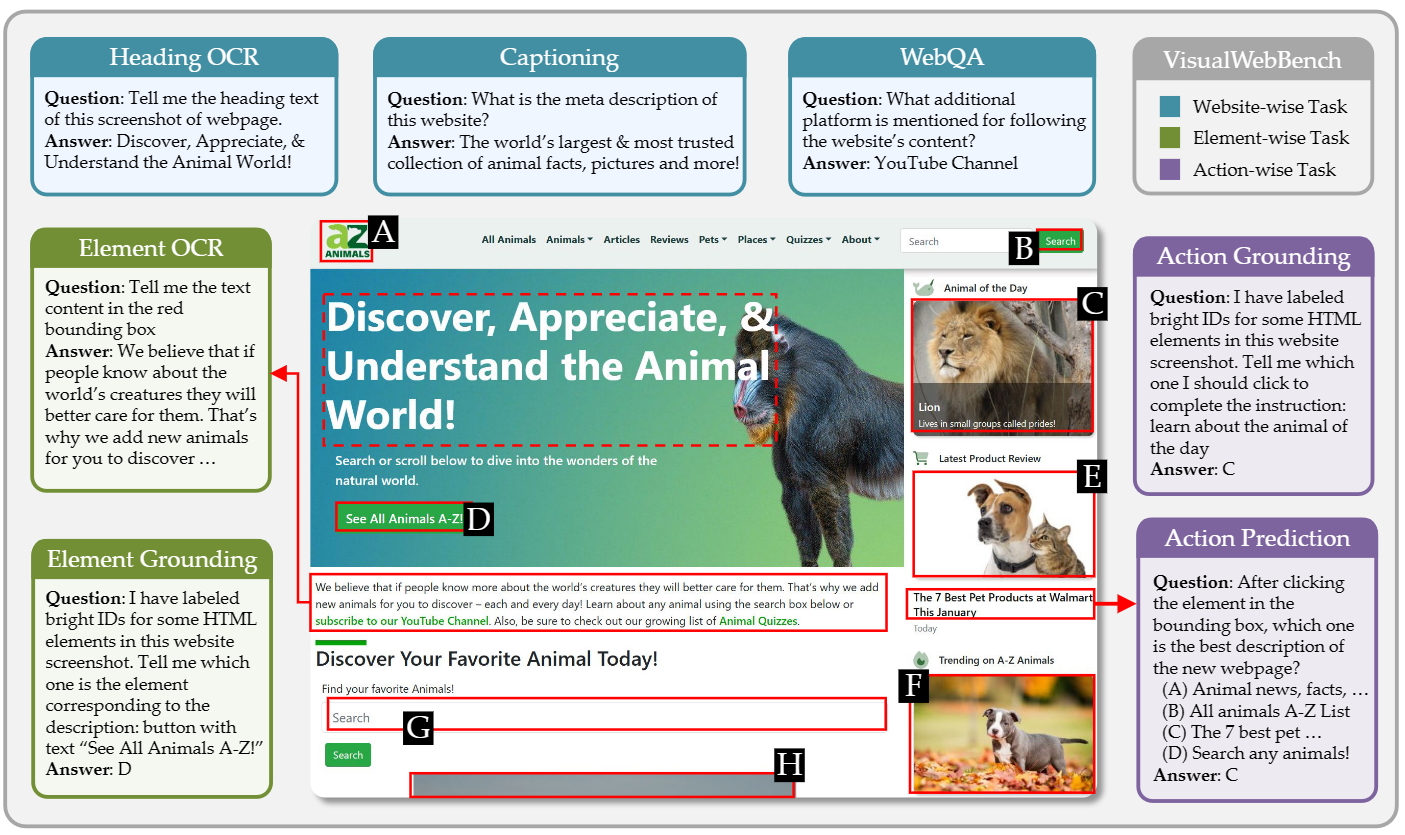
We introduce VisualWebBench, a multimodal benchmark designed to assess the understanding and grounding capabilities of MLLMs in web scenarios. VisualWebBench consists of seven tasks, and comprises 1.5K human-curated instances from 139 real websites, covering 87 sub-domains. We evaluate 14 open-source MLLMs, Gemini Pro, Claude 3, and GPT-4V(ision) on VisualWebBench, revealing significant challenges and performance gaps. Further analysis highlights the limitations of current MLLMs, including inadequate grounding in text-rich environments and subpar performance with low-resolution image inputs. We believe VisualWebBench will serve as a valuable resource for the research community and contribute to the creation of more powerful and versatile MLLMs for web-related applications.
2024/10/18: We introduce 🤗 MultiUI, 7.3M general multimodal instructions synthesized from webUIs using text-based LLMs, enhancing both UI-related and Doc/OCR/chart understanding tasks.
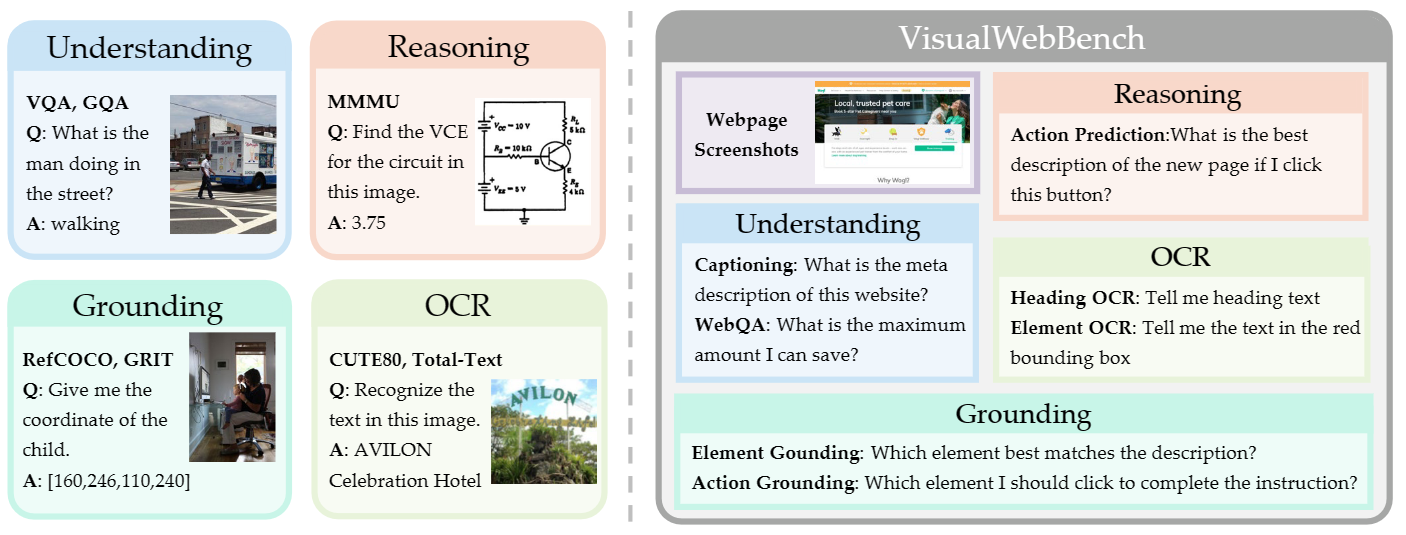
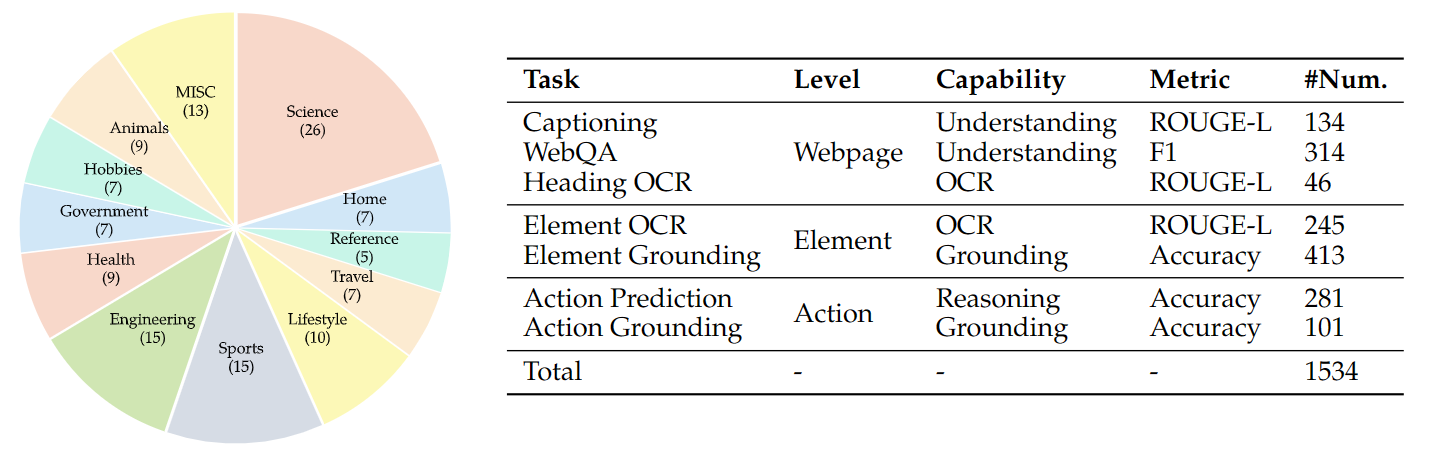
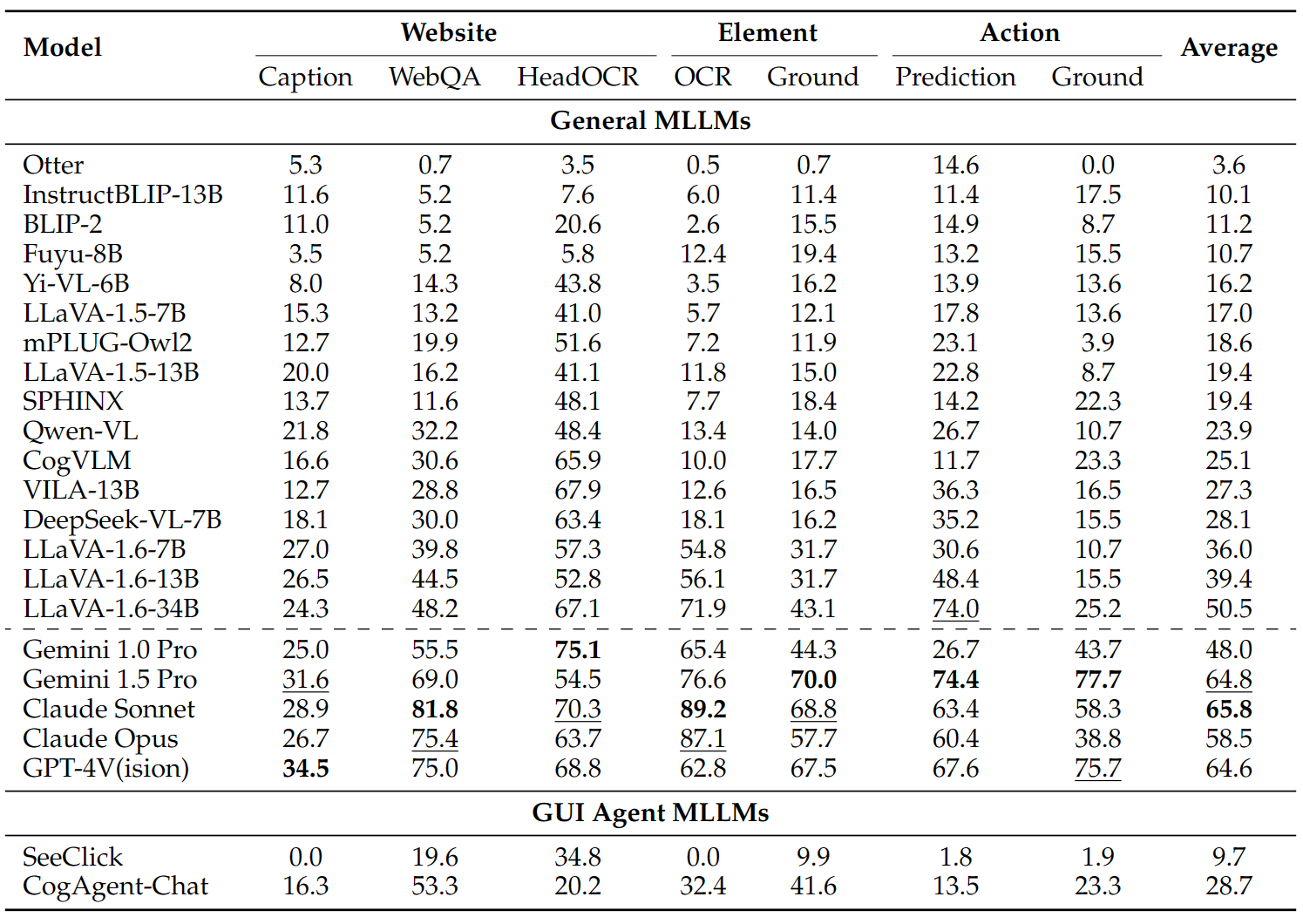
We evaluate 14 open-source general MLLMs on VisualWebBench. By default, for each model family, we use the largest available checkpoint. We consider three scales of LLaVA, 7B, 13B, and 34B, for model scaling analysis. Several strong close-source MLLMs, Gemini Pro, Claude series, and GPT-4V(ision), are also included for evaluation. In addition, we evaluate 2 GUI agent MLLMs, i.e., CogAgent and SeeClick, on VisualWebBench.



@misc{liu2024visualwebbench,
title={VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?},
author={Junpeng Liu and Yifan Song and Bill Yuchen Lin and Wai Lam and Graham Neubig and Yuanzhi Li and Xiang Yue},
year={2024},
eprint={2404.05955},
archivePrefix={arXiv},
primaryClass={cs.CL}
}